



Pandas is a great Python library to work with data. Here I will give a brief introductory overview of Pandas based on the tutorial I just finished. I downloaded a random dataset on 100 countries and types of items they sell. Also, later I learned that Kaggle has loads of public datasets to use. Open up a Jupyter notebook and follow along!
Firstly, you want to run your Jupyter notebook from the folder where you have your dataset stored. In my case, I used sales.csv file to practice on.
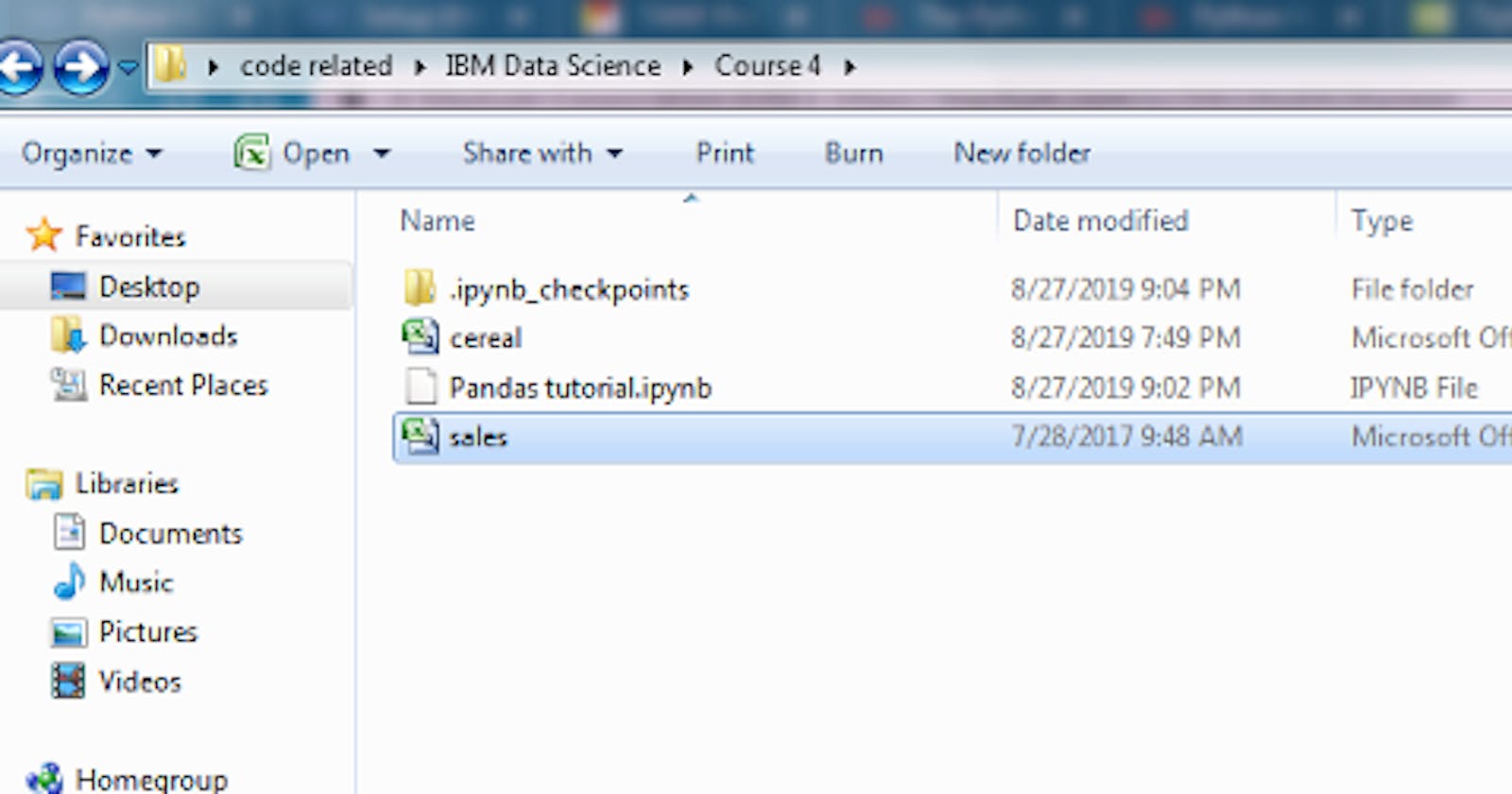
My dataset “sales.csv”
In my Jupyter notebook I listed out the column names in my dataset in Markdown. If you are using a more personal and familiar dataset, you can add description for each column as well.
Next up, we will import Pandas library and execute it by pressing Shift+Enter. We will save it as “pd” to save us time.

Let’s save our file path in a variable “csv_path” as follows:

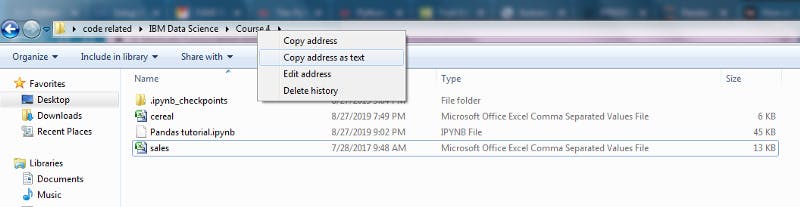
Here is how I found the path. Right click the folder name you in and choose “Copy address as text”. Then just add your file name at the end of your address.
Now we will save the contents of our file in a “df” variable, which is short for “dataframe”. You can use any other variable here though. We will also equal “error_bad_lines” to False to skip over null cells, so that the execution does not stop.

In order to see the contents of our file, we will use head() function. This will only allow us to see the first 5 rows of data.

Here is the output:
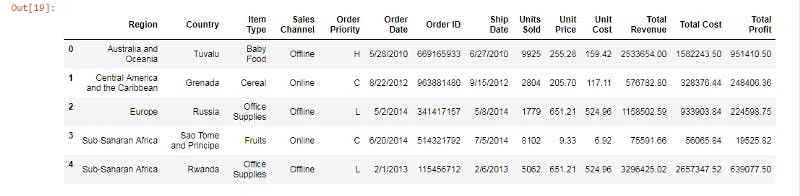
1st 5 rows of data with all 14 columns.
Let’s access a “Country” column:

There are 100 countries here so the list goes really long. But here is the output of the first 13 rows:

Here is how to get the same column as one-dimensional dataframe with the accompanying output:

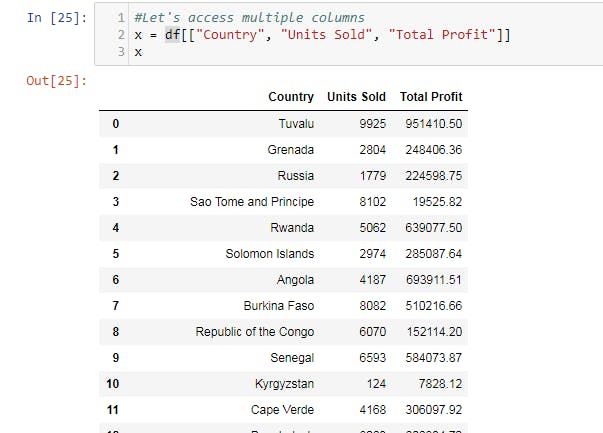
In order to get several columns, we just add the names of columns and store all of it in a variable:
iloc[] function allows us to access a specific cell by using 2 numbers. For instance, iloc(0,0) gets us the first row from the first column. Remember to count from 0.

loc[] function is handy when using the name of the column. loc[4, “Country”] fetches the 5th country from the “Country” column, which is “Rwanda”:

You can also perform slicing on the dataframe just like you would with a regular array or dictionary. Use numbers for the rows and columns, or numbers and column names:

This is it! Go check out the link below to complete the Quiz on Python’s Pandas library:
sseidmed/python_learning
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…github.com